KDE, because despite my bitterness for the loss of Unity 8, I know it’s merely nostalgia for me. I want something I feel like I can make my own without too much difficulty.
nek0d3r
- 0 Posts
- 27 Comments
Joined 1 year ago
Cake day: July 11th, 2023
You are not logged in. If you use a Fediverse account that is able to follow users, you can follow this user.
Alright this has me giggling this morning

This has been a dream of mine and one of my friend’s as well. There’s a small handful of blockers that I’ve slowly been transitioning but the upcoming windows pain points you mentioned are definitely recent motivators for me. I’m glad you made it and I hope the rest of us can too! I look forward to reading more about your experience.

 3·1 month ago
3·1 month agoThe source is literally just VSCode with a different label. What benefit does that have?
That’s a truly awful take. Especially for people who have since learned to be more mindful about their data. We need solidarity to fight corporations, not punitive treatment.

Right, exactly, which is why they launched with a FOSS license. Oh, wait–
Imagine the money going to VSCode which actually is the one getting contributions
Except this isn’t money going to a FOSS project, it’s money to some guys whose only keyboard is StackOverflow’s The Key.
Don’t do that. Don’t give me hope.

That’s basically it. Some Arch users are genuinely just picky about what they want on their system and desire to make their setup as minimal as possible. However, a lot of people who make it their personality just get a superiority complex over having something that’s less accessible to the average user.
 5·3 months ago
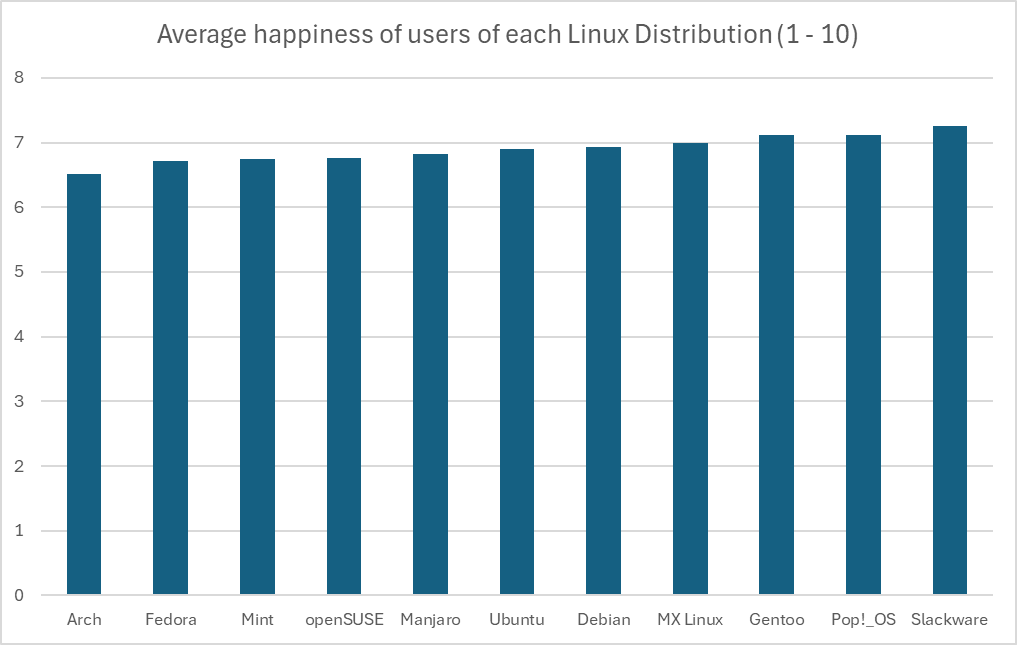
5·3 months agoThere’s not a lot of data to work with, and the kind of test used to determine significance is not the same across the board, but in this case you can do an analysis of variance. Start with a null hypothesis that the happiness level between distros are insignificant, and the alternative hypothesis is that they’re not. Here are the assumptions we have to make:
- An alpha value of 0.05. This is somewhat arbitrary, but 5% is the go-to threshold for statistical significance.
- A reasonable sample size of users tested for happiness, we’ll go with 100 for each distro.
- A standard deviation between users in distro groups. This is really hard to know without seeing more data, but as long as the sample size was large enough and in a normal distribution, we can reasonably assume s = 0.5 for this.
We can start with the total mean, this is pretty simple:
(6.51 + 6.71 + 6.74 + 6.76 + 6.83 + 6.9 + 6.93 + 7 + 7.11 + 7.12 + 7.26) / 11 = 6.897Now we need the total sum of squares, the squared differences between each individual value and the overall mean:
Arch: (6.51 - 6.897)^2 = 0.150 Fedora: (6.71 - 6.897)^2 = 0.035 Mint: (6.74 - 6.897)^2 = 0.025 openSUSE: (6.76 - 6.897)^2 = 0.019 Manjaro: (6.83 - 6.897)^2 = 0.005 Ubuntu: (6.9 - 6.897)^2 = 0.00001 Debian: (6.93 - 6.897)^2 = 0.001 MX Linux: (7 - 6.897)^2 = 0.011 Gentoo: (7.11 - 6.897)^2 = 0.045 Pop!_OS: (7.12 - 6.897)^2 = 0.050 Slackware: (7.26 - 6.897)^2 = 0.132This makes a total sum of squares of 0.471. With our sample size of 100, this makes for a sum of squares between groups of 47.1. The degrees of freedom for between groups is one less than the number of groups (
df1 = 10).The sum of squares within groups is where it gets tricky, but using our assumptions, it would be:
number of groups * (sample size - 1) * (standard deviation)^2Which calculates as:
11 * (100 - 1) * (0.5)^2 = 272.25The degrees of freedom for this would be the number of groups subtracted from the sum of sample sizes for every group (
df2 = 1089)Now we can calculate the mean squares, which is generally the quotient of the sum of squares and the degrees of freedom:
# MS (between) 47.1 / 10 = 4.71 // Doesn't end up making a difference, but just for clarity # MS (within) 272.25 / 1089 = 0.25Now the F-statistic value is determined as the quotient between these:
F = 4.71 / 0.25 = 18.84To not bog this down even further, we can use an F-distribution table with the following calculated values:
- df1 = 10
- df2 = 1089
- F = 18.84
- alpha = 0.05
According to the linked table, the F-critical value is between 1.9105 and 1.8307. The calculated F-statistic value is higher than the critical value, which is our indication to reject the null hypothesis and conclude that there is a statistical significance between these values.
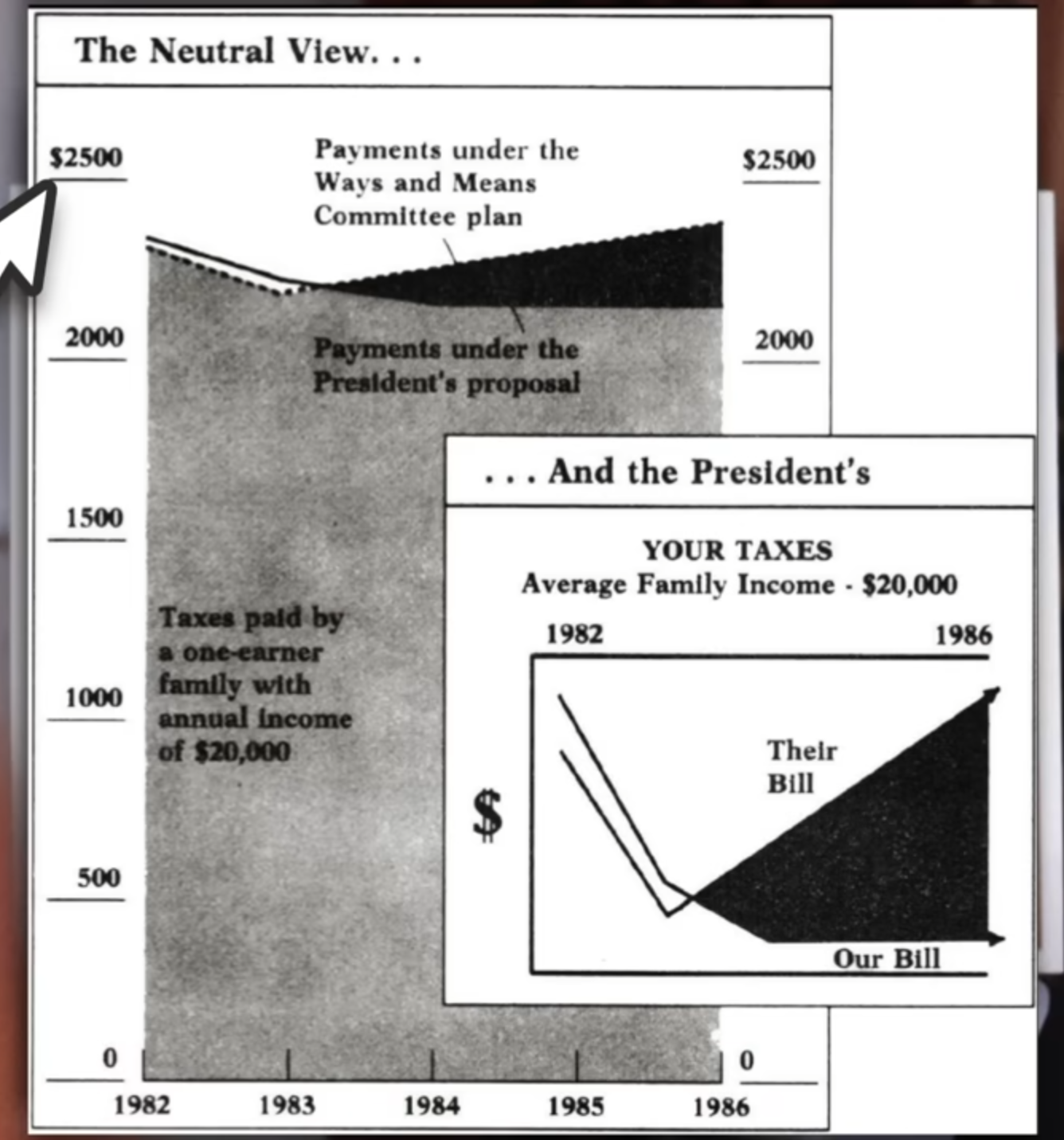
However, again you can see above just how many assumptions we had to make, that the distribution of the data within each group was great in number and normally varied. There’s just not enough data to really be sure of any of what I just did above, so the only thing we have to rely on is the representation of the data we do have. Regardless of the intentions of whoever created this graph, the graph itself is in fact misrepresent the data by excluding the commonality between groups to affect our perception of scale. There’s a clip I made of a great example of this:
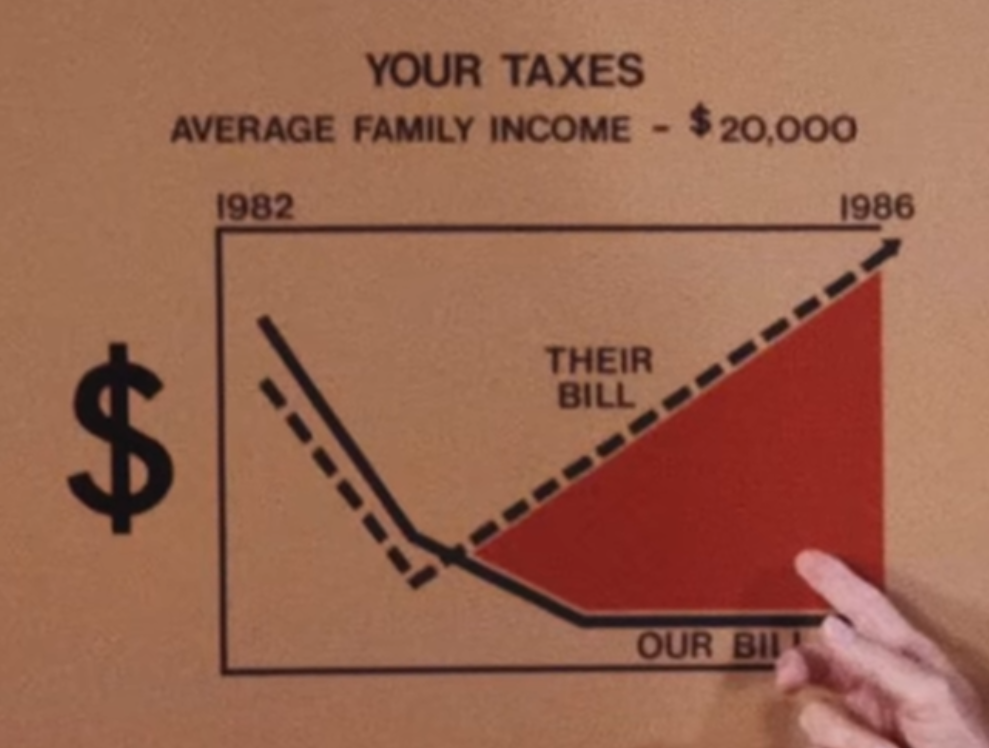
There’s a pile of reasons this graph is terrible, awful, no good. However, it’s that scale of the y-axis I want to focus on.
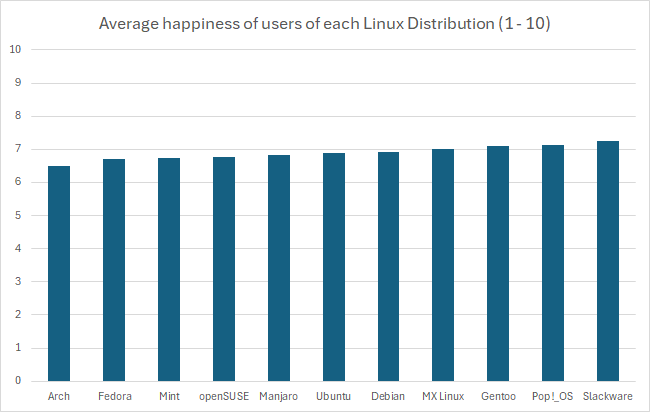
This is an egregious example of this kind of statistical manipulation for the point of demonstration. In another comment I ended up recreating this bar graph with a more proper scale, which has a lower bound of 0 as it should. It’s suggested that these are values out of 10, so that should be the upper bound as well. That results in something that looks like this:
In fact, if you wanted you could go the other way and manipulate data in favor of making something look more insignificant by choosing a ridiculously high upper bound, like this:
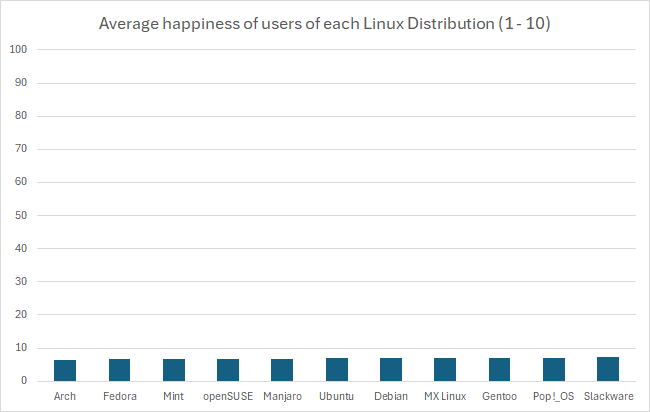
But using the proper scale, it’s still quite difficult to tell. If these numbers were something like average reviews of products, it would be easy in that perspective to imagine these as insignificant, like people are mostly just rating 7/10 across the board. However, it’s the fact that these are Linux users that makes you imagine that the threshold for the differences are much lower, because there just aren’t that many Linux users, and opinions wildly vary between them. This also calls into question how that data was collected, which would require knowing how the question was asked, and how users were polled or tested to eliminate the possibility of confounding variables. At the end of the day I just really could not tell visually if it’s significant or not, but that graph is not a helpful way to represent it. In fact, I think Excel might be to blame for this kind of mistake happening more commonly, when I created the graph it defaulted the lower bound to 6. I hope this was helpful, it took me way too much time to write 😂
Just to kind of demonstrate that idea, I’ve recreated the graph in Excel with the axis starting at 0. I think Excel might actually be to blame for this happening so much, its auto selection actually wanted to pick 6, gross.
Sometimes it’s hard to tell the difference between arch and some gentoo users
Fair enough, it’s just one of those distros you find a lot of those elitists in. Even had a “friend” tell me I wasn’t really a Linux user because I don’t use arch, then gentoo, then openbsd
 3·3 months ago
3·3 months agoYeah, effectively I’d want to use it as you could on Wii U, both displaying the second screen and interacting with the touchscreen. Splatoon in particular is extremely underrated with second screen use, being able to see and interact with the map in real-time is so much more useful than blocking your screen in future Splatoon games
Definitely, I think there was even a hacked splatfest at one point, which would be SO cool to do regularly. I just meant to say that, as far as I’ve seen, the gamepad can’t easily be used to play with if you were to emulate.
I know the differences between these metrics are inconsequential because the happiness view doesn’t start at 0, but it still makes me want to shout “what the fuck are gentoo users so happy about” lol
I don’t really know about the uptick, but the general trend upward over a longer period of time I kind of wonder if it’s due to things like the steam deck. I played around with gaming in Linux with wine back in the early 2010s and was woefully unimpressed with how little I could do, especially with the amount of work involved. I didn’t really give it a second look at all, but after the deck released I was blown away by how much has improved, and it’s motivated me to see how much I can get away with without windows. I wonder how many people have had a similar experience.
Side note, if anyone knows how I can play Splatoon on an emulator using my Wii U gamepad, I’m all ears lol
I have a friend like this, I’m a Nintendo collector and enjoying the hardware is my hobby. I know it’s an expensive endeavor, and I don’t expect anyone else to do it. I genuinely think any game should be up for piracy and emulation support, and it’s incredible what can be done to make games look, sound, and play better than the original. But when I’m sitting there having fun with Metroid Fusion on my GBA SP and you sit there going “why would you ever do that when emulating is cheaper and better” I don’t think you’re conversing in good faith.
Same here! I’m happy to see the UBports fork is still active as Lomiri, I haven’t checked it out in a while.