Well this is local LLM, which isn’t the same as sending everything to ChatGPT. I’ve been experimenting with Ollama to run some local LLMs and it’s pretty neat, I can see it becoming pretty useful in a few years when performance and memory requirements improve- there have already been big advances for the local stuff this year. I’m curious how exactly it’ll be used in opera- I’ll at least check it out.
A local LLM is still made up of data scraped from across the internet. Especially not keen on anything that straps Facebook and Google directly to the browser.


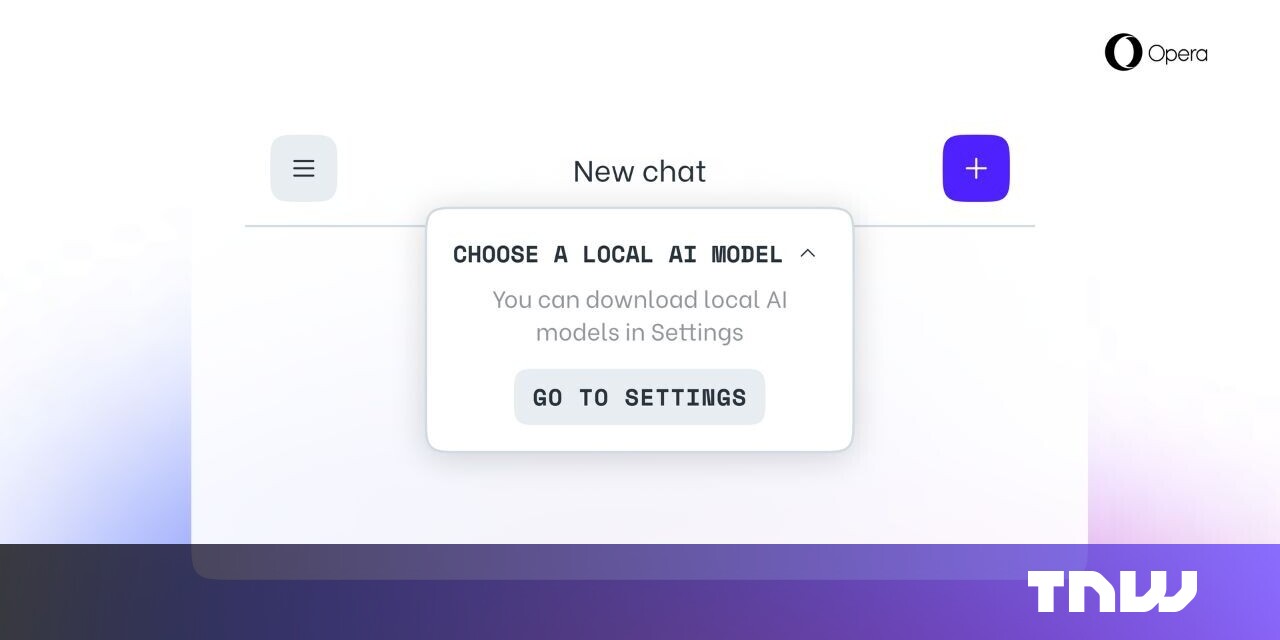
Well this is local LLM, which isn’t the same as sending everything to ChatGPT. I’ve been experimenting with Ollama to run some local LLMs and it’s pretty neat, I can see it becoming pretty useful in a few years when performance and memory requirements improve- there have already been big advances for the local stuff this year. I’m curious how exactly it’ll be used in opera- I’ll at least check it out.
Have you heard of 1 bit LLMs? It’s crazy !
https://medium.com/ai-insights-cobet/no-more-floating-points-the-era-of-1-58-bit-large-language-models-b9805879ac0a
That’s pretty amazing and I suspect that’ll be a trend that continues at a pretty rapid pace!
A local LLM is still made up of data scraped from across the internet. Especially not keen on anything that straps Facebook and Google directly to the browser.